SpringCloud微服务实战——搭建企业级开发框架(四十六):使用Actuator+Prometheus+Grafana实现完整的微服务监控告警系统
SpringCloud微服务实战——搭建企业级开发框架(四十六):使用Actuator+Prometheus+Grafana实现完整的微服务监控告警系统
无论是使用SpringBootAdmin还是使用Prometheus+Grafana都离不开SpringBoot提供的核心组件Actuator。提到Actuator,又不得不提Micrometer,从SpringBoot2.x开始,Actuator的功能实现都是基于Micrometer的。
Micrometer通过仪表客户端为各种健康监控系统提供了一个简单的外观Facade(Facade模式是23种设计模式中的一种,也叫外观模式 / 门面模式,Facade(外观)模式为子系统中的各类(或结构与方法)提供一个简明一致的界面,隐藏子系统的复杂性,使子系统更加容易使用。它是为子系统中的一组接口所提供的一个一致的界面。)。
类似于SLF4J,我们可以自由选择log4j2、logback等日志框架一样,Micrometer支持灵活切换或者多种并存的健康监控系统检测基于 JVM 的应用程序。
Micrometer提供的功能:
- 尺寸指标(Dimensional Metrics):Micrometer 为计时器、仪表、计数器、分布摘要和长任务计时器提供了与供应商无关的接口,具有维度数据模型,当与维度监控系统配对时,允许有效访问特定命名的度量,并具有向下钻取的能力跨越其维度。
- 预配置绑定(Pre-configured Bindings):开箱即用的缓存、类加载器、垃圾收集、处理器利用率、线程池等工具,更适合可操作的洞察力。
- Spring集成(Integrated into Spring):Micrometer 是一个检测库,支持从 Spring Boot 应用程序交付应用程序指标。
Micrometer支持的监控系统:
AppOptics, Azure Monitor, Netflix Atlas, CloudWatch, Datadog, Dynatrace, Elastic, Ganglia, Graphite, Humio, Influx/Telegraf, JMX, KairosDB, New Relic, Prometheus, SignalFx, Google Stackdriver, StatsD, and Wavefront.
上文中我们说明了如何搭建Spring Boot Admin的微服务健康检查监控系统,简单的应用使用Spring Boot Admin即可,复杂的集群应用建议使用Micrometer 支持的多种灵活可配的监控系统,这里我们选择目前使用比较广泛的Prometheus+Grafana监控系统。
两种方式都能够实现微服务的健康检查统计展示和告警,Prometheus+Grafana在功能和界面美观上更强大一些,并且可以查看历史数据,而SpringBootAdmin优点是部署十分简单,不需要部署太多的环境软件,本身就是一个微服务。在两种方式的选择上,如果是小的项目,比如单体应用,双击热备,前期可以先使用SpringBootAdmin,随着业务的发展,可以考虑使用Prometheus+Grafana。
一、Prometheus+Grafana相关介绍
1、Prometheus介绍
Prometheus: 是一款开源的系统和服务监控系统,属于云原生计算基金会项目。它可以通过设置的时间间隔从配置的目标系统采集指标数据,保存指标数据(时序数据库),评估规则表达式,显示结果,并在检测到指定条件时触发警报。
- 多维数据模型:Prometheus 实现了一个高维数据模型,它从根本上将所有数据存储为时间序列:属于同一指标和同一组标记维度的时间戳值。 除了存储的时间序列,Prometheus 可能会生成临时派生的时间序列作为查询的结果。
- 高效存储:Prometheus 以高效的自定义格式将时间序列存储在内存和本地磁盘上(内置TSDB数据库,同时也提供了远程存储接口),扩展是通过功能分片和联合来实现的。
- PromQL:一种强大且灵活的查询语言,PromQL 允许对收集的时间序列数据进行切片和切块,以生成临时图形、表格和警报。
- 不依赖分布式存储,操作简单:每台服务器的可靠性都是独立的,仅依赖于本地存储。用 Go 编写,所有二进制文件都是静态链接的,易于部署。
- HTTP拉取模型: 通过抓取HTTP端点采集时序数据。
- 通过用于批处理作业的中间网关支持推送时间序列数据。
- 通过服务发现或静态配置发现目标。
- 出色的可视化:Prometheus 有多种数据可视化模式,内置表达式浏览器、Grafana 集成和控制台模板语言。
- 支持分层和水平联合。
2、Grafana介绍
虽然Prometheus也支持可视化界面展示,但是界面不美观,更多人选择使用Grafana来展示Prometheus的监控数据。
Grafana:Grafana是一款开源的数据可视化工具。它提供对数据指标的查询、可视化和告警,它可以实现无论数据存储在哪里,都可以与您的团队创建、探索和共享十分美观的仪表盘数据可视化,并培养数据驱动的文化。
- 可视化:具有多种选项的快速灵活的客户端图表。面板插件提供了许多不同的方式来可视化指标和日志。
- 动态仪表板:使用在仪表板顶部显示为下拉列表的模板变量创建动态和可重复使用的仪表板。
- 探索指标:通过即席查询(是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表)和动态钻取探索您的数据。拆分视图并并排比较不同的时间范围、查询和数据源。
- 探索日志:体验从指标切换到带有保留标签过滤器的日志的魔力。快速搜索所有日志或实时流式传输它们。
- 告警:为您最重要的指标直观地定义告警规则。Grafana 将持续评估并向 Slack、PagerDuty、VictorOps、OpsGenie 等系统发送通知。
- 混合数据源:在同一个图中混合不同的数据源!您可以基于每个查询指定数据源。这甚至适用于自定义数据源。
二、使用Docker安装配置Prometheus+Grafana
我们使用Docker来安装需要的Prometheus+Grafana,通常情况下,我们会根据业务需求来安装需要的组件,在这里健康监控系统也是这样,如果我们的微服务部署在Docker容器中,那么我们需要安装cAdvisor组件来监控Docker相关数据指标,如果要采集系统环境数据,那么需要安装 Node Exporter 组件,而且告警组件也是和Prometheus分开的,如果需要告警功能,同样需要安装Alertmanager组件,这一连串组件的组合,自然让我们想到使用docker-compose来安装我们需要所有组件。
参考 github.com/stefanproda… 我们编写两个docker-compose文件:
- 服务端:数据采集、展示、告警,安装 prometheus、grafana、cadvisor、alertmanager、node-exporter、caddy
- 客户端: 只需安装 cadvisor、node-exporter用于采集本机数据。
1、准备Docker宿主主机的安装部署目录。
# 创建prometheus挂在目录
mkdir /data/monitor/prometheus
cd /data/monitor/prometheus
touch prometheus.yml
mkdir /data/monitor/prometheus_data
# 创建alertmanager挂在目录
mkdir -p /data/monitor/alertmanager
# 创建grafana挂在目录
mkdir -p /data/monitor/grafana_data
mkdir -p /data/monitor/grafana/provisioning/dashboards
mkdir -p /data/monitor/grafana/provisioning/datasources2、编写docker-compose-prometheus-server.yml,此处为服务编排模板参考,因某些原因docker镜像仓库无法访问,需切换到能够访问到的镜像仓库。
- docker-compose-prometheus-server.yml
version: '3.2'
networks:
monitor-net:
driver: bridge
volumes:
prometheus_data: {}
grafana_data: {}
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- /data/monitor/prometheus:/etc/prometheus
- /data/monitor/prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/consoles'
- '--storage.tsdb.retention.time=200h'
- '--web.enable-lifecycle'
restart: unless-stopped
expose:
- 9090
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
volumes:
- /data/monitor/alertmanager:/etc/alertmanager
command:
- '--config.file=/etc/alertmanager/config.yml'
- '--storage.path=/alertmanager'
restart: unless-stopped
expose:
- 9093
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
nodeexporter:
image: prom/node-exporter:latest
container_name: nodeexporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
restart: unless-stopped
expose:
- 9100
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
privileged: true
devices:
- /dev/kmsg:/dev/kmsg
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
#- /cgroup:/cgroup:ro #doesn't work on MacOS only for Linux
restart: unless-stopped
expose:
- 8080
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
grafana:
image: grafana/grafana:latest
container_name: grafana
volumes:
- /data/monitor/grafana_data:/var/lib/grafana
- /data/monitor/grafana/provisioning/dashboards:/etc/grafana/provisioning/dashboards
- /data/monitor/grafana/provisioning/datasources:/etc/grafana/provisioning/datasources
environment:
- GF_SECURITY_ADMIN_USER=${ADMIN_USER:-admin}
- GF_SECURITY_ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin}
- GF_USERS_ALLOW_SIGN_UP=false
restart: unless-stopped
expose:
- 3000
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
pushgateway:
image: prom/pushgateway:latest
container_name: pushgateway
restart: unless-stopped
expose:
- 9091
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
caddy:
image: caddy:latest
container_name: caddy
ports:
- "3000:3000"
- "9090:9090"
- "9093:9093"
- "9091:9091"
volumes:
- ./caddy:/etc/caddy
environment:
- ADMIN_USER=${ADMIN_USER:-admin}
- ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin}
- ADMIN_PASSWORD_HASH=${ADMIN_PASSWORD_HASH:-JDJhJDE0JE91S1FrN0Z0VEsyWmhrQVpON1VzdHVLSDkyWHdsN0xNbEZYdnNIZm1pb2d1blg4Y09mL0ZP}
restart: unless-stopped
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"在服务端安装执行安装命令:
docker-compose -f docker-compose-prometheus-server.yml up -d执行会报错,因无法访问部分docker镜像库:Error response from daemon: Get "gcr.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers),请自行设置将docker切换到能够访问的云服务器。
3、编写docker-compose-prometheus-client.yml,此处为服务编排模板参考,因某些原因docker镜像仓库无法访问,需切换到能够访问到的镜像仓库。
version: '3.2'
services:
nodeexporter:
image: prom/node-exporter:latest
container_name: nodeexporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
restart: unless-stopped
network_mode: host
labels:
org.label-schema.group: "monitoring"
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
privileged: true
devices:
- /dev/kmsg:/dev/kmsg
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /cgroup:/cgroup:ro
restart: unless-stopped
network_mode: host
labels:
org.label-schema.group: "monitoring"在服务端安装执行安装命令:
docker-compose -f docker-compose-prometheus-server.yml up -d同在服务端执行一样,这里执行会报错,请自行切换可以访问到的镜像仓库。
4、以上为生产环境所需的安装方式配置参考,下面我们使用Docker进行最小安装,来测试运行Prometheus+Grafana。
- 执行安装Prometheus
docker run -d \
--restart=always \
-u root \
--name prometheus \
-p 9090:9090 \
-v /etc/localtime:/etc/localtime \
-v /data/monitor/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /data/monitor/prometheus_data:/prometheus \
prom/prometheus- 执行安装Grafana
docker run -d \
--restart=always \
-u root \
--name grafana \
-p 3000:3000 \
-v /data/grafana_data:/var/lib/grafana \
-v /data/grafana/provisioning/dashboards:/etc/grafana/provisioning/dashboards \
-v /data/grafana/provisioning/datasources:/etc/grafana/provisioning/datasources \
-e GF_SECURITY_ADMIN_USER=${ADMIN_USER:-admin} \
-e GF_SECURITY_ADMIN_PASSWORD=${ADMIN_PASSWORD:-admin} \
-e GF_USERS_ALLOW_SIGN_UP=false \
grafana/grafana5、安装成功后访问链接查看是否成功
- Prometheus: http://192.168.0.10:9090/
- Grafana:http://192.168.0.10:3000/ ,通过我们安装时部署的用户名密码: admin / admin 登录。

三、微服务相关配置及添加Prometheus支持
1、在gitegg-platform-bom工程中引入micrometer的prometheus依赖包。
请注意,在选择micrometer-registry-prometheus版本时,一定要和框架中SpringBoot引入的micrometer相匹配的版本,否则不兼容。
......
<!-- prometheus 微服务监控 和 spring-boot-admin二选一-->
<micrometer.registry.prometheus.version>1.5.14</micrometer.registry.prometheus.version>
......
<!-- actuator prometheus 健康检查https://mvnrepository.com/artifact/io.micrometer/micrometer-registry-prometheus -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
<version>${micrometer.registry.prometheus.version}</version>
</dependency>
......2、gitegg-cloud工程的父pom.xml统一引入prometheus依赖包,这样,我们就可以统一灵活切换使用的监控系统。
<!-- 如果使用prometheus进行健康检查,这里统一引入依赖。如果使用SpringBootAdmin,这里注释掉。-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>3、修改Nacos,开启prometheus抓取端点。
metrics.tags.application: ${spring.application.name} 设置tag方便Prometheus抓取数据时区分不同的服务。
# 性能监控端点配置
management:
security:
enabled: true
role: ACTUATOR_ADMIN
endpoint:
health:
show-details: always
endpoints:
enabled-by-default: true
web:
base-path: /actuator
exposure:
include: '*'
metrics:
tags:
application: ${spring.application.name}
export:
prometheus:
enabled: true
server:
servlet:
context-path: /actuator
health:
mail:
enabled: false4、查看启动结果 http://127.0.0.1:8002/actuator/prometheus

四、配置Prometheus+Grafana采集并展示微服务健康监控数据
1、编辑prometheus配置文件prometheus.yml,设置采集微服务端点
scrape_configs:
- job_name: 'actuator-gitegg'
basic_auth:
username: user
password: password
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['192.168.0.2:80','192.168.0.2:8002']- basic_auth:设置采集端点的basic认证信息
- metrics_path:设置prometheus采集端点的路径
- static_configs.targets: 设置prometheus采集端点的地址
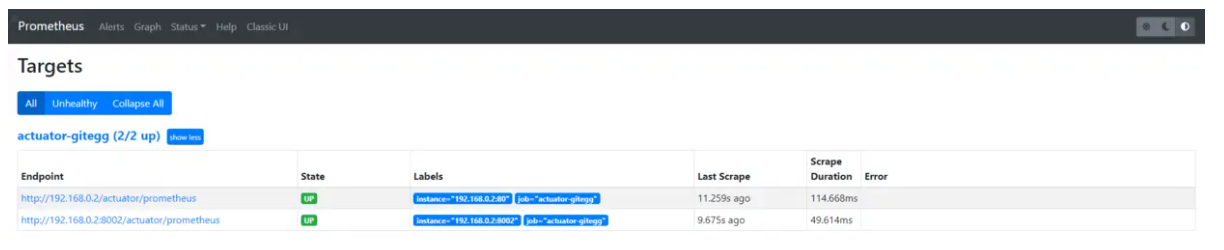
2、重启prometheus,访问界面status -> targets,查看采集端点状态。
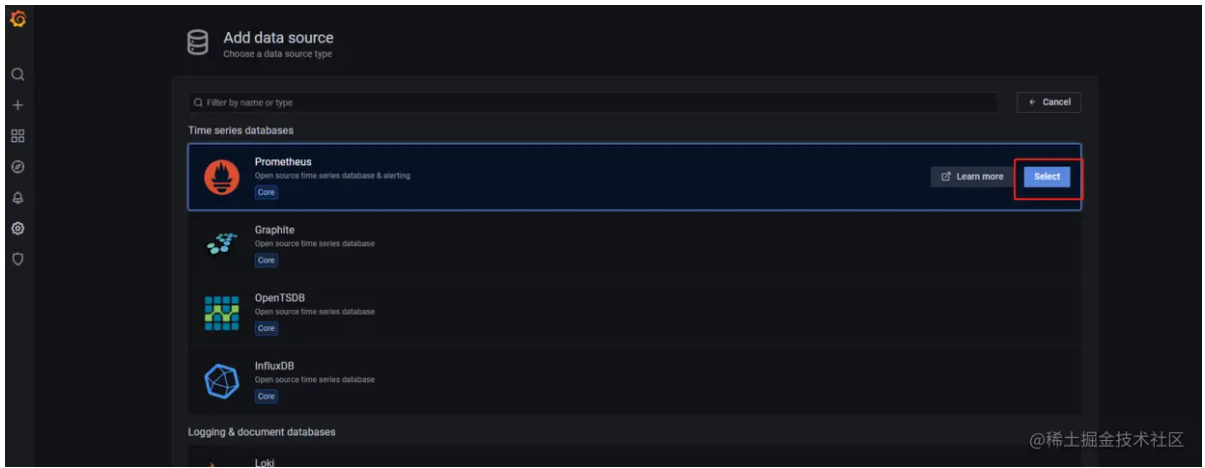
3、配置Grafana,添加prometheus数据源并展示JVM监控图表。
- Configuration -> Data sources -> Add data source

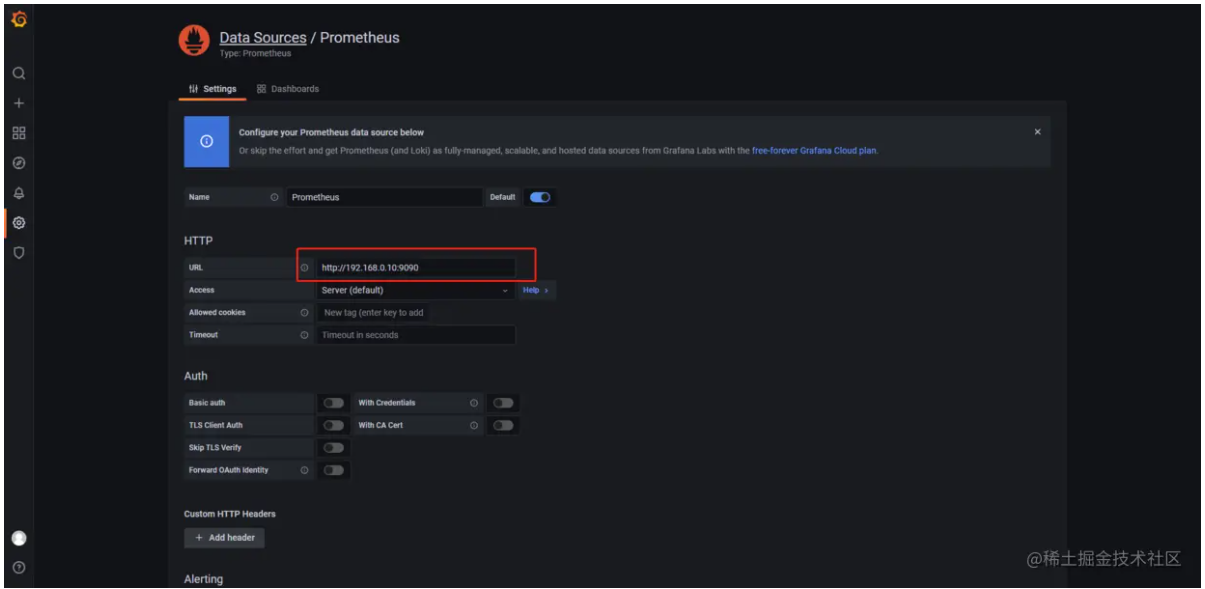
- 添加Prometheus数据源地址 http://192.168.0.10:9090/
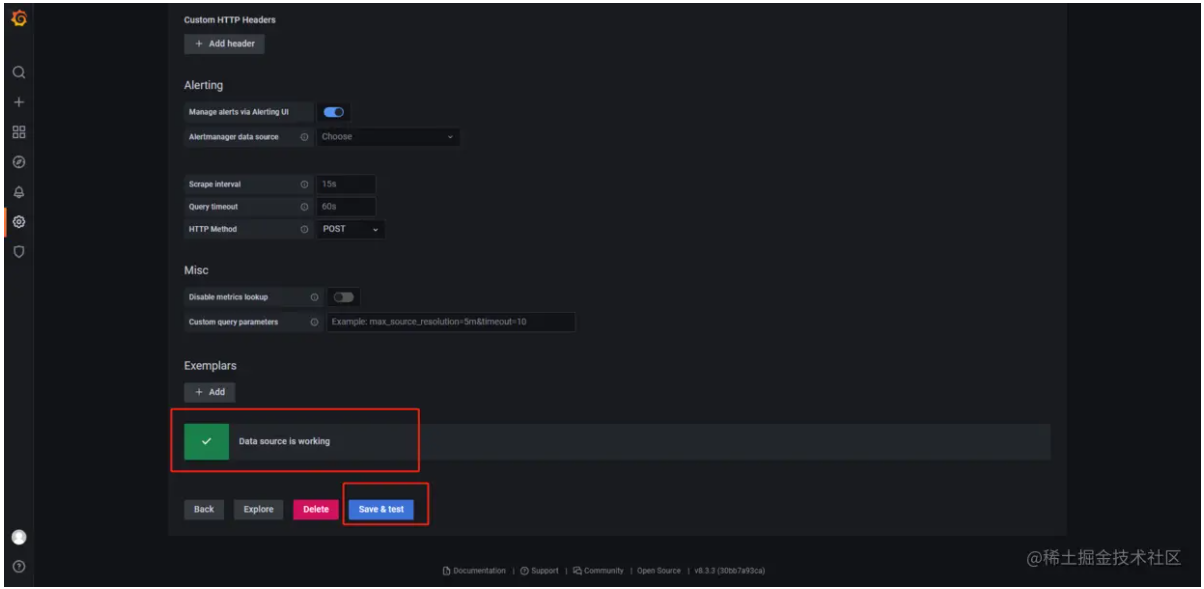
- Import 仪表盘,Grafana提供了很多内置的仪表盘模板,官方模板地址:grafana.com/grafana/das… , 我们这里选择使用JVM (Micrometer)模板,输入模板的地址grafana.com/grafana/das… 或者模板的编号4701,然后点击Load进行加载。

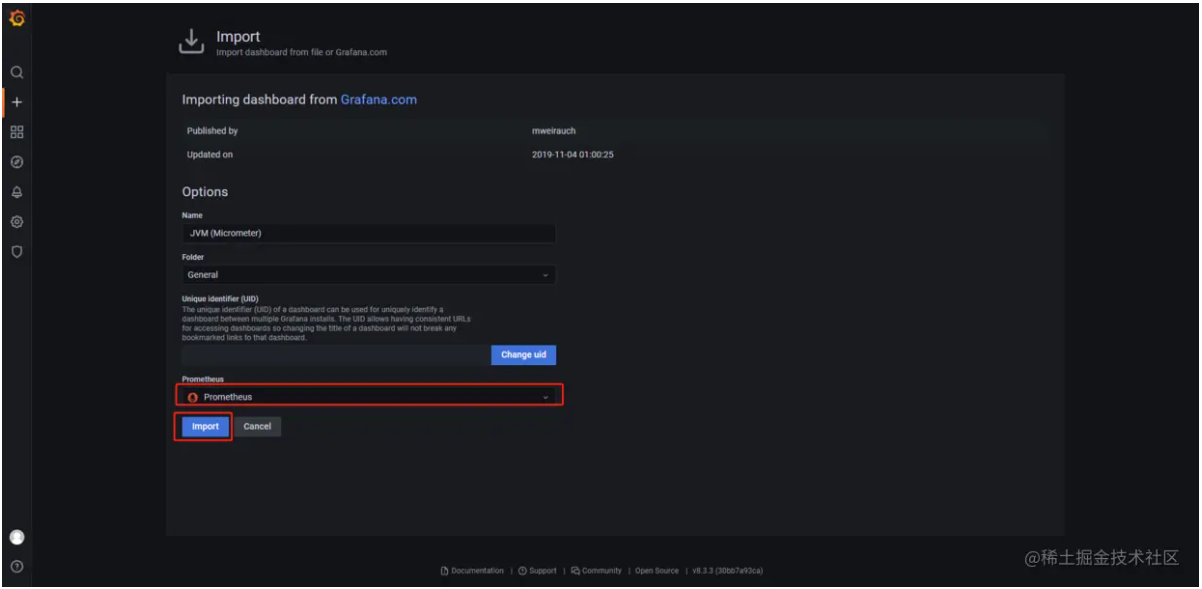
- 执行import后就可以看到我们导入的仪表盘模板了,点击右上角的Save进行保存。
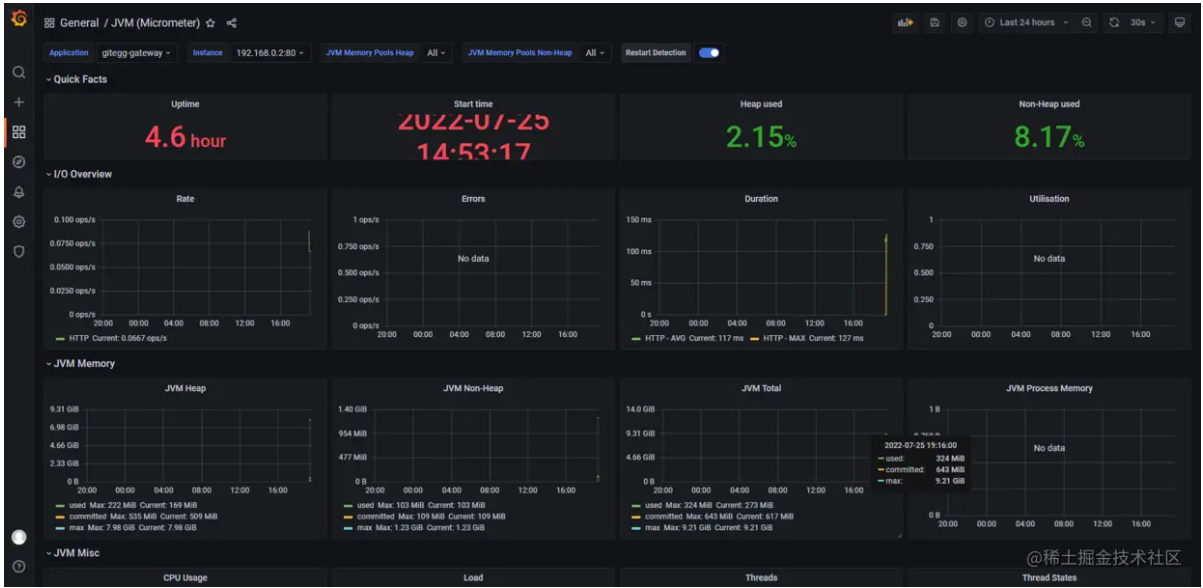
通过以上步骤已经能够搭建和配置简单的Actuator(Micrometer)+ Prometheus + Grafana 微服务健康监控系统,查看Prometheus / Grafana 官方文档,我们可以知道其提供的功能非常丰富,在实际使用过程中,我们需要根据自己的业务需求进行更细维度的部署和配置。
服务健康监控系统是保障我们系统服务正常运行的必要工具,配置部署非常方便,但是,我们生产环境一定要注意系统安全问题,不要把健康检查的端点暴露出去,该做鉴权的做鉴权,该做安全防护的做安全防护,不要因为方便健康监控而增加安全风险。